

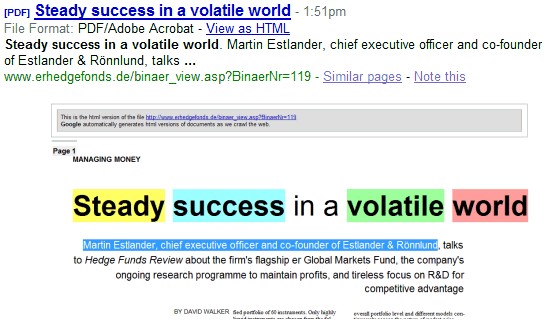
 "Önceden, içeriklerinde ne olduğunu tam olarak bilemediğimizden taralı belgeler arama sonuçlarında nadiren yer alıyordu. Bugün, bu durum değişiyor. Artık, Adobe'un PDF formatında yedeklenmiş olarak bulunan herhangi bir taranmış belgede Optical Character Recognition (OCR - Optik Karakter Tanıma) işlemini gerçekleştirebiliyoruz."
"Önceden, içeriklerinde ne olduğunu tam olarak bilemediğimizden taralı belgeler arama sonuçlarında nadiren yer alıyordu. Bugün, bu durum değişiyor. Artık, Adobe'un PDF formatında yedeklenmiş olarak bulunan herhangi bir taranmış belgede Optical Character Recognition (OCR - Optik Karakter Tanıma) işlemini gerçekleştirebiliyoruz."
Bu Optik Karakter Tanıma teknolojisi, Google'a bir belgenin resmini, belgenin içinde yer alan kelimelere dönüştürme imkânı tanıyor.
Google, her ne kadar PDF formatlarında kaydedilen belgeleri bir süredir indeksliyorsa da, bir bilgisayarın taranmış belgeleri okuması çok daha zor.
Tarama işlemi, yazma işleminin tam tersidir. Yazma işleminde dijital kelimeler, kâğıtta bir metne dönüşür. Taramada ise fiziksel bir kâğıdın (ve metnin) dijital bir fotoğrafı yaratılarak bu fotoğrafı bilgisayarınızda kaydetme ve görüntüleme olanağına sahip olursunuz.
Ancak metnin taranmış resmi, orijinal dijital kelimelerin aynısı değildir diyor Google ve, "Genellikle sırrı açığa çıkaran işaretleri görürsünüz: Bir kahve kupasının bıraktığı leke, mürekkep lekesi ve hatta sayfalarda kat izine bile rastlayabilirsiniz.
Bu belgeyi okuyan kişiler için kelimelerle kelimelerin resimleri arasında ufak bir fark vardır, fakat bir bilgisayar göre bu resim neredeyse anlaşılmazdır.
Bu teknoloji binlerce kelimeden oluşan bir resmi gerçekten aranabilen ve endekslenebilen binlerce kelimeye dönüştürebiliyor. Böylece değerli dokümanların bulunması daha kolaylaşıyor. Bu beceri, dünyadaki tüm bilgiyi ulaşılabilir ve kullanılabilir kılma misyonumuz için küçük ama çok önemli bir adım." yorumunu yapıyor.
Yeni teknoloji sayesinde devlet raporlarından akademik belgelere kadar birçok önemli bilgi gün ışığına çıkacak.
Google taranmış belgeleri de listeleyecek...
Ekleyen
robutGüncelleme Zamanı
08.09.2009Google, arama sonuçlarında bundan böyle taranmış belgeleri de gösterecek.